Purpose
This paper will discuss SQL (ODBC) maps and outline general information necessary to complete a SQL map. The paper will also cover the flow of the translator for outbound SQL (ODBC) Maps and how to use the components available with the SQL File Format to design a map to process the result set returned via the SQL statement defined in the map.
The concepts listed in this paper are focused towards outbound SQL maps; however some of the information provided is related to inbound SQL maps.
The concepts discussed in this paper apply to ODBC maps created in Gentran:Server for Windows (GSW) and SQL maps created in Gentran Integration Suite (GIS).
Background
SQL maps are maps that use the SQL (ODBC) File Format on the input side or output side of the map. Maps with the SQL File Format for the input side of the map will retrieve and process data from a database. Maps with the SQL File Format for the output side of the map will add/update/delete data in the database.
The SQL data format enables you to create a map directly from a database schema, which saves time and ensures that the map is synchronized with the most current version of the database. You can also specify several data sources allowing the map to query or update multiple databases during translation.
General Information
SQL/ODBC maps that access the databases installed with any Sterling Commerce product are Not Supported.
SQL/ODBC maps that utilize a system DSN and/or JDBC pools created for use with any installed Sterling Commerce product are Not Supported.
User IDs and passwords used in a SQL Map need to have the appropriate permissions to execute the SQL commands specified in the map.
SQL Statements
- SQL Statements must be complete and must return the proper result set outside of the Map Editor before a map can be designed with them.
- Modifications and/or debugging of the SQL statements utilized in a map are Not Supported.
- SQL Statements that return a result set cannot be used on the output side of the map.
- SQL statements defined within SQL/ODBC Maps cannot be dynamic. The translator does not contain functionality to pass values between the map and a SQL statement. If a value is needed in a SQL statement it must be hard coded.
- When working with multiple SQL statements in a map that return a result set, use the ORDER BY clause to return all result sets in the same order. This will help prevent undesired output results from the map.
- Maps that use TRUNCATE statements cannot be rolled back if a translation error occurs.
- Do not place SQL statements inside of repeating groups. The translator will execute the SQL statement for each occurrence of the group which is not efficient and since SQL statements cannot be dynamic in a map the result set will always be the same.
When the output side of the map is SQL
- Remember to link like data types
- Remember not to link fields where the input value is greater in length than the database column permits.
- Map a value to all NOT NULL columns in the table that the map writes to.
iSeries Database Files Requirements
- All iSeries Database files that are accessed via a SQL/ODBC map are required to be journaled.
GIS Specific Information
The Map Editor, used to create maps, is Windows-based, and uses Open Database Connectivity (ODBC) to connect to external databases.
Gentran Integration Suite is Java-based, and uses Java Database Connectivity (JDBC) to connect to external databases. Type-4 JDBC Drivers are required to connect to the database.
If the SQL syntax is used on both sides of a map, each side must use a separate set of data sources. One side cannot refer to the data sources belonging to the other side of the map.
In Release 4.0 and higher of GIS the translation service will re-invoke the map and use the result set rather than re-executing the SQL statement to pull a new result set.
- Due to this behavior change, the translation service parameter ‘exhaust_input’ does not need to be set to ‘NO’ if the map does not contain an Update record.
- The Map Test functionality behaves in the same manner.
- The Map Test Functionality should only be used to test a map with a small batch of data in the tables. If the amount of data to retrieve is large the map should be checked into GIS so it can be tested from a BP.
- If the map contains multiple SQL queries a ‘Move Next’ cursor operation must be present in the map for each query. When the map is re-invoked the cursor will then be on the row of the result set it was on at the end of the previous transaction.
The translator operates in transactional mode and will roll back any database updates if the process fails as long as the following parameters are set.
- In the map the DSN must have the option ‘Use Transaction’ checked.
- The ‘type’ parameter in the JDBC pool must be set to ‘local’.
GIS Outbound Process Flow
Below is a general process flow for how the translator processes a SQL map in GIS Release 4.0 and higher.
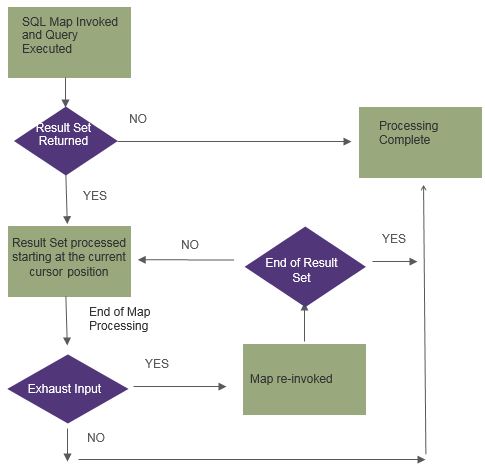
GSW Specific Information
The Map Editor, used to create maps, is Windows-based, and uses Open Database Connectivity (ODBC) to connect to external databases.
The translator operates in transactional mode and will roll back any database updates if the process fails as long as the DSN in the map has the option ‘Use Transaction’ checked.
Maps that use the SQL syntax on the output side must be created as Export maps.
Maps that use the SQL syntax on the input side must be created as Import maps.
Maps that utilize the SQL syntax on both sides are Not Supported.
Outbound Processing
The System Import Header Map and Import Map design drive when translation is complete for Outbound ODBC Mapping, not the translator.
The translator does not contain functionality that indicates which rows in the database have been processed. Therefore, the records that have been processed must be marked or flagged, so the translator processes only the rows that should be processed.
- To mark records as processed or not processed, designate a column in the database table to contain a processing flag. This can be a column that the user inserts into the database table or it could be an existing unused column in the table.
- This column must then be incorporated into the SQL statement record in the map the retrieves the data. This column must also be updated from within the map to indicate that the row of data was processed.
When processing an outbound ODBC Map, if the database will contain data that does not have a valid partner relationship the System Import Header and Import maps will need to be configured to handle this scenario. The maps must be set up to expect this scenario; otherwise an infinite loop will result.
- Please see the White Paper ‘doc’, located on Support on Demand, for specifics on how to configure the maps to handle this scenario.
Inbound Processing
If there are any errors during the Export process, they will be listed in the Translator Report found in the External Data Browser. This browser is similar to the Interchange Browser. The below audit message is issued when compliance errors are encountered during the export process.
- Audit Message #: 3-1-1754
- Error Message: Translation error during document export. Export file %1, external data key %2, partner %3, document name %4
GIS Outbound Process Flow
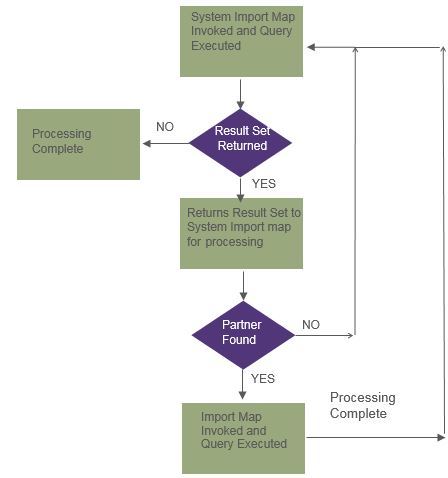
SQL Map Implementation
The translator processes an outbound SQL map differently from a map that uses a file as input. When the translator processes a map that takes a file as the input, it automatically reads the segments from the input file. However, when the translator processes an outbound SQL map, it does not automatically move to the next row in the result set. The map must be designed to tell the translator when to move to the next row of the result set.
SQL Statements
Outbound SQL Maps must contain a SQL statement that returns the correct result set before the map can be properly created.
When selecting from more than one table in the select list, each row of the result set will contain data from all columns listed in the select list of the SQL statement. The result set data is in a relational format and not a hierarchical format.
Result Sets
The result set produced by the SQL statement will contain a set of rows from the database. Each row of the result set contains information from all tables listed in the ‘From’ list of the SQL statement. Parent information will repeat for each unique row of child information.
Map Design
The map will control how the translator processes the result set returned by the SQL statement.
SQL Input Records
Input records are used to map data from the result set. Each input record defined in the map is not required to contain all columns available in the result set. It only needs to contain those columns from which data should be mapped at that level.
When working with a result set that contains parent/child data, the input records that will map the child data will utilize Key Fields to keep this relationship in tact when processing through the result set.
SQL Output Records
Output records are used to write to the database. Output records are most commonly used in Outbound SQL maps to update rows in the database indicating that the row has been processed by the translator. If this is not done, each time the SQL statement is executed the same result set will be returned.
When working with output records on the intput side of the map, at least one field in the record must be associated with a query. If no fields are associated with a query the record is a temporary record and the translator will not execute it.
Cursor Operations
Cursor operations tell the translator to move to a new row of the result set. The map can use a manual cursor operation or the “Automatically get next row from statement record” option available on the Looping tab in the properties of an Input record and Output record can be selected.
If the map does not contain a cursor operation to move though the result set the translator will never move off row one in the result set. This can cause an infinite loop in translation.
Key Fields
SQL maps contain Key Field functionality to match against fields that appear previously in the map; up to three Key Fields can be used.
When mapping from a join of master-detail records to an equivalent hierarchy, the translator can determine when the keys in the detail level no longer match the keys in the master level. The Key Field selection on a record should be related to the criteria in the ‘Where’ clause of the SQL statement.
Note: Key fields are intended to be used with string fields only. If a numeric field is used as a key field, the result is not guaranteed.
The ‘Key Field #’ drop down lists will display all fields for the current record.
The ‘Use Field #’ drop down lists will display all fields in all records previous to the current record.
The translator processes the ‘Use Field’ Key Fields in the following manner.
- Obtain the value for the field listed in the ‘Key Field’ drop down box from the corresponding column in the current row of the result set.
- Obtain the value for the field listed in the ‘Use Field’ drop down box from the translator memory storage for the record that contains the field.
- Compare the two values:
- If the values match, process the record.
- If the ‘Automatically get next row from statement record’ check box is selected move the cursor to the next row of the result set.
- If the values do not match, do not process the record.
- The translator will not move the cursor to the next row of the result set if the ‘Automatically get next row from statement record’ check box is selected.
- If the values match, process the record.
Note: If more than one key field is specified on the record, the translator will attempt to match all key fields, in order, before processing the record.
Click below to find out more what Appleyard’s EDI Services can do for you
